红黑树查询:其访问性能近似于折半查找,时间复杂度 O(logn); 链表查询:这种情况下,需要遍历全部元素才行,时间复杂度 O(n);
”AS ash hash hashmap 红黑树 链表“ 的搜索结果

详细解读了HashMap中链表转红黑树的treefyBin方法,该方法中涉及到的诸如:replacementTreeNode方法、treeify方法、comparableClassFor方法、compareComparables方法、tieBreakOrder方法、balanceInsertion方法、...

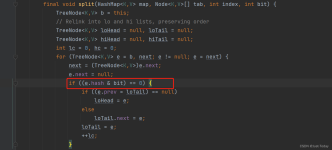

扩容 resize( ) 时,红黑树拆分成的 树的结点数小于等于临界值6个,则退化成链表。 移除元素 remove( ) 时,在removeTreeNode( ) 方法会检查红黑树是否满足退化条件,与结点数无关。 扩容 resize( ) 的源码分析 ...

HashMap 链表与红黑树转换

红黑树中的TreeNode是链表中的Node所占空间的2倍,虽然红黑树的查找效率为o(logN),要优于链表的o(N),但是当链表长度比较小的时候,即使全部遍历,时间复杂度也不会太高。固,要寻找一种时间和空间的平衡,即在链表...
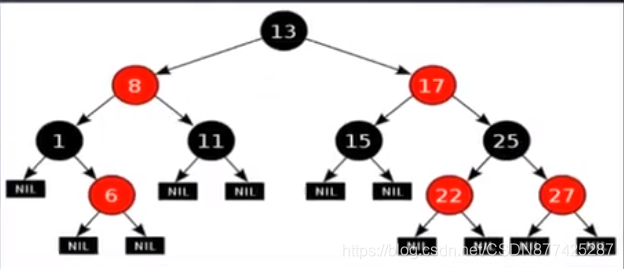
红黑树是一种自平衡的二叉搜索树,它是一种在插入和删除操作时能够自我调整以保持平衡的数据结构。红黑树之所以称为红黑树,是因为每个节点都具有颜色属性,可以是红色或黑色,这些颜色属性必须满足一定的约束条件,...
* 可以是一个链表,也可以是一颗红黑树,此时为红黑树)中将红黑树分割成两棵树, *一颗为高位树hi,一颗为低位树lo,如果hi或者lo树节点太小,该树将会退化为链表 * 再移动到新哈希表中,该方法仅在resize()方法...

从内核中单独将红黑书和链表抽出来,可以直接include使用,不需要依赖其他头文件。
通过查看源码可以发现,默认是链表长度达到 8 就转成红黑树,而当长度降到 6 就转换回去,这体现了时间和空间平衡的思想,最开始使用链表的时候,空间占用是比较少的,而且由于链表短,所以查询时间也没有太大的问题...
一般情况下,HashMap底层使用数组+链表,当数据量非常大时,长度大的链表(大于8)自动转成红黑树,此时,HashMap底层使用数组+链表+红黑树。至于这个阈值是系统设置的。当链表长度降到6时就自动转换回链表。通常...

【Java】为什么1.8中HashMap链表转换成红黑树的阈值是8,红黑树转链表的阈值是6?
链表和红黑树测试代码
标签: 链表和红黑树
linux内核双向环形链表和红黑树,源码学习,摘录部分代码编译成库,进行测试
时间和空间的权衡,因为红黑树需要进行左旋,右旋操作, 而hashmap选择红黑树,为啥hashmap不直接采用红黑树,为什么达到8个才转红黑树_宁为百夫长的博客-程序员宅基地_hashmap为什么不直接用红黑树不需要,TreeNodes...


常见的数据结构(栈、队列、数组、链表和红黑树) 数组和链表.pdf
HashMap在JDK1.8之后引入了红黑树的概念,表示若桶中链表元素超过8时(并且数组的大小是64),会自动转化成红黑树;若桶中元素小于等于6时,树结构还原成链表形式。那具体的原因是因为什么呢? 1.红黑树的平均查找...
链表转红黑树是链表长度达到阈值,为什么阈值为8?不是其他数字 链表转红黑树是链表长度达到阈值是8,红黑树转链表阈值为6。 因为经过计算,在hash函数设计合理的情况下,发生hash碰撞8次的几率为百万分之6,用概率...
总结一下:jdk1.8中HashMap底层链表转红黑树的阈值为什么是8?链表查询慢为啥不直接用红黑树? 1、红黑树插入效率慢,例如我插入一个001、002、003会进行左旋,进行数据交换,效率较低,阈值为8是想达到一个平衡。 ...
HashMap中链表转为红黑树的条件 HashMap的底层是元素为链表的数组。 转化条件 在JDK1.8之后,HashMap中的链表在满足以下两个条件时,将会转化为红黑树(即自平衡的排序二叉树): 1. 条件一 数组 arr[i] 处存放的...
推荐文章
- 阿里云企业邮箱的stmp服务器地址_阿里云stmp地址-程序员宅基地
- c++ 判断数学表达式有效性_高考数学大题如何"保分"?学霸教你六大绝招!...-程序员宅基地
- 处理office365登录出现服务器问题_o365登陆显示网络异常-程序员宅基地
- Nginx RTMP源码分析--ngx_rtmp_live_module源码分析之添加stream_ngx_rtmp_live_module 原理-程序员宅基地
- 基于Ansible+Python开发运维巡检工具_automation_inspector.tar.gz-程序员宅基地
- Linux Shell - if 语句和判断表达式_shell if elif-程序员宅基地
- python升序和降序排序_Python排序列表数组方法–通过示例解释升序和降序-程序员宅基地
- jenkins 构建前执行shell_Jenkins – 在构建之前执行脚本,然后让用户确认构建-程序员宅基地
- 如何完全卸载MySQL_mysql怎么卸载干净-程序员宅基地
- AndroidO Treble架构下HIDL服务查询过程_found dead hwbinder service-程序员宅基地